En el ecosistema digital actual, donde plataformas de ecommerce, servicios de streaming y aplicaciones web procesan millones de visitas diarias, comprender el comportamiento de los usuarios se ha convertido en un imperativo estratégico. Sin embargo, las herramientas tradicionales de analítica como Google Analytics o Matomo, aunque poderosas, presentan limitaciones críticas cuando se trata de arquitecturas de alta concurrencia que demandan control total sobre los datos, trazabilidad granular y toma de decisiones en tiempo real.
En este artículo, exploraremos las estrategias de Fingerprint y HIT Tracking, analizaremos por qué son esenciales para sistemas de alta escala, y examinaremos una arquitectura de referencia que combina FingerprintJS, PostgreSQL, Redis y Go para construir un sistema de tracking robusto, escalable y de bajo latencia.

El Problema con las Herramientas Tradicionales de Analítica
Google Analytics y Matomo: Potentes pero Limitadas
Herramientas como Google Analytics y Matomo son ampliamente utilizadas y ofrecen dashboards intuitivos, informes predefinidos y facilidad de implementación. Sin embargo, presentan desafíos significativos para organizaciones que operan a gran escala:
1. Dependencia de Terceros y Privacidad de Datos Con Google Analytics, los datos de tus usuarios se envían a servidores de Google, lo que puede generar problemas de cumplimiento con regulaciones como GDPR, especialmente en Europa. Aunque Matomo ofrece autoalojamiento, su arquitectura no está optimizada para escenarios de ultra-alta concurrencia.
2. Latencia y Agregación de Datos Estas herramientas agregan datos antes de presentarlos, lo que significa que pierdes granularidad a nivel de cada visita individual. Para casos de uso como detección de fraude, personalización en tiempo real o análisis de patrones de comportamiento sospechosos, necesitas acceso inmediato a datos sin procesar.
3. Limitaciones de Integración Las APIs de estas herramientas tienen límites de rate limiting y no siempre permiten la integración profunda con sistemas propietarios, machine learning pipelines o infraestructuras de decisión en tiempo real.
4. Costo en Escala Para volúmenes de tráfico masivos (decenas de millones de eventos diarios), las versiones enterprise de estas herramientas pueden resultar prohibitivamente caras.
El Caso para Fingerprint y HIT Tracking Personalizado
Una estrategia de Fingerprint combinada con HIT Tracking te permite:
- Control Total: Los datos nunca salen de tu infraestructura
- Granularidad Completa: Cada visita, cada clic, cada evento se registra sin agregación
- Latencia Ultra-Baja: Decisiones en milisegundos, no en minutos u horas
- Escalabilidad Ilimitada: Diseñado desde cero para manejar millones de eventos concurrentes
- Costos Predecibles: Pagas solo por tu infraestructura (compute, storage, cache)
¿Qué es el Fingerprinting y por qué es Crucial?
Concepto de Browser Fingerprinting
El fingerprinting es una técnica que permite identificar de forma única un navegador web (y por extensión, a un visitante) basándose en características técnicas del dispositivo, sin necesidad de cookies ni almacenamiento local. Estas características incluyen:
- Configuración del navegador (user agent, plugins, fuentes instaladas)
- Resolución de pantalla y profundidad de color
- Zona horaria y configuración de idioma
- Canvas fingerprinting (renderizado de gráficos)
- WebGL fingerprinting (capacidades de la GPU)
- Audio context fingerprinting
- Detección de bloqueadores de anuncios o VPNs
Herramientas como FingerprintJS generan un hash único combinando estas características, lo que permite identificar al mismo visitante incluso si borra cookies o navega en modo incógnito.
Ventajas del Fingerprinting sobre Cookies
Persistencia: A diferencia de las cookies, que pueden ser borradas, el fingerprint se regenera cada visita y permanece consistente siempre que el usuario no cambie significativamente su configuración.
Resistencia a Bloqueadores: Los bloqueadores de cookies no afectan al fingerprinting basado en características del navegador.
Linking Cross-Device (con cuidado): Aunque el fingerprint cambia entre dispositivos, puedes vincularlo cuando el usuario se autentica, creando un perfil unificado.
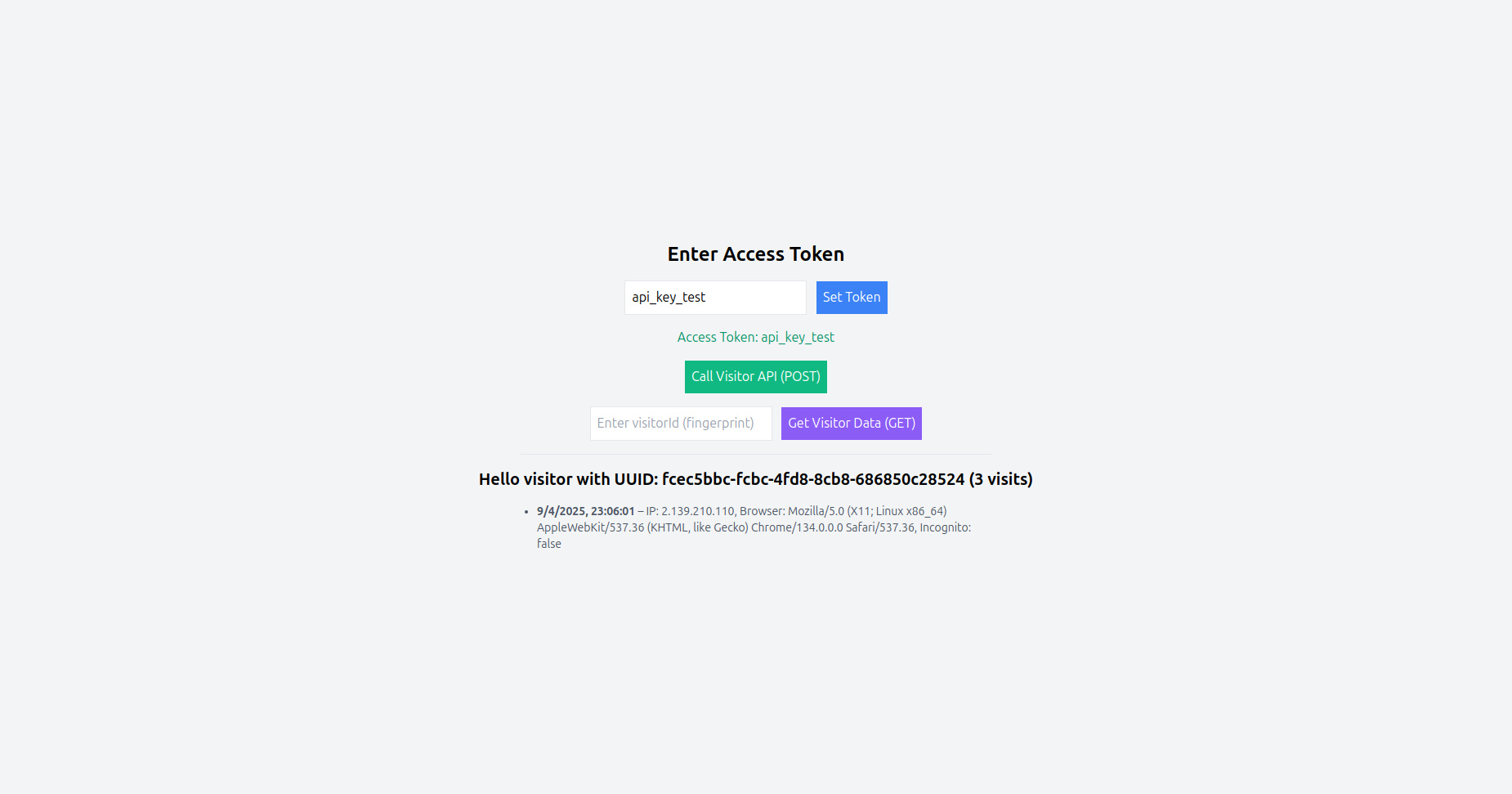
HIT Tracking: El Corazón del Sistema de Analítica
¿Qué es un HIT?
En el contexto de analítica web, un HIT (o “visit event”) es un registro individual de una interacción del usuario con tu plataforma. Cada vez que un visitante:
- Carga una página
- Hace clic en un elemento
- Reproduce un video (en streaming)
- Añade un producto al carrito (en ecommerce)
- Completa una transacción
Se genera un HIT que contiene metadata rica:
{
"timestamp": "2025-10-10T11:23:45Z",
"visitor_id": "550e8400-e29b-41d4-a716-446655440000",
"fingerprint": "a1b2c3d4e5f6...",
"ip": "203.0.113.45",
"ip_country": "ES",
"browser_name": "Chrome",
"browser_version": "118.0",
"os": "Windows",
"os_version": "11",
"url": "/products/smart-tv-4k",
"origin": "https://www.example.com",
"incognito": false,
"vpn_detected": false,
"user_id": "usr_7890abcd" // si está autenticado
}
Importancia de los HITs para Decisiones en Tiempo Real
1. Detección de Fraude en Ecommerce Supongamos que detectas múltiples HITs desde diferentes fingerprints pero con la misma IP y comportamiento sospechoso (añadir productos al carrito sin completar compra, intentar usar múltiples tarjetas). Puedes bloquear la transacción en tiempo real.
2. Personalización de Contenido en Streaming Si un visitante ha visto 3 episodios de una serie de ciencia ficción (registrado en HITs), puedes recomendarle contenido similar en su próxima visita, incluso antes de que inicie sesión.
3. Análisis de Patrones de Navegación Al almacenar la URL de cada HIT, puedes construir mapas de calor de navegación, identificar páginas con alta tasa de abandono, o descubrir paths óptimos de conversión.
4. Geolocalización y Compliance Si un visitante accede desde un país con restricciones regulatorias (ip_country), puedes ajustar el contenido mostrado o bloquear ciertas funcionalidades automáticamente.
Arquitectura de Referencia: Sistema de Fingerprint/HIT de Alta Concurrencia
Vamos a analizar una arquitectura real construida con Go, PostgreSQL, Redis (Valkey) y FingerprintJS que puede procesar millones de HITs por día con latencias por debajo de 10ms.
Componentes de la Arquitectura
1. Cliente: FingerprintJS En el frontend, la biblioteca FingerprintJS se ejecuta al cargar cada página y genera un hash único del navegador. Este fingerprint, junto con metadata adicional (URL actual, origin, etc.) se envía al backend mediante una petición HTTP POST.
// Ejemplo simplificado de integración
import FingerprintJS from '@fingerprintjs/fingerprintjs';
const fp = await FingerprintJS.load();
const result = await fp.get();
await fetch('/api/visitor', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
fingerprint: result.visitorId,
url: window.location.href,
origin: window.location.origin,
userId: getCurrentUserId() // si está autenticado
})
});
2. API Backend: Go con Echo Framework El backend recibe el payload y procesa el HIT en tres pasos:
- Lookup de Visitante: Consulta si el fingerprint ya existe en la base de datos
- Generación de UUID: Si es un nuevo visitante, se genera un UUID único que se convierte en el
visitor_iddefinitivo - Enriquecimiento de Datos: Se obtiene la IP real del visitante (considerando proxies y CDNs), se determina el país mediante geolocalización, se detecta si usa VPN o modo incógnito
- Persistencia Multi-Capa: Se guarda el HIT en PostgreSQL y se actualiza el caché en Redis
// Fragmento simplificado del handler
func VisitorHandler(c echo.Context) error {
var payload FingerprintPayload
c.Bind(&payload)
clientIP := deriveClientIP(c) // Extrae IP real
ipCountry := getIPCountryWithFallback(clientIP) // Geolocalización
currentEvent := VisitEvent{
Timestamp: time.Now().UTC(),
IP: clientIP,
IPCountry: ipCountry,
URL: payload.URL,
// ... más campos
}
// Buscar o crear visitor_id
visitorID := lookupOrCreateVisitor(payload.Fingerprint)
// Persistir HIT
insertVisitEvent(db, visitorID, currentEvent)
// Actualizar caché
cacheVisitor(redis, visitorID)
return c.JSON(200, Response{UUID: visitorID, HitCount: newHitCount})
}
3. Caché Multi-Nivel
Nivel 1: Caché en Memoria (In-Process) Para visitantes frecuentes, se mantiene un mapa en memoria que evita consultas a Redis o PostgreSQL en cada HIT. Esto reduce latencia a < 1ms para visitantes recurrentes.
Nivel 2: Redis (Valkey) Redis actúa como caché distribuido con TTL de 10 minutos. Cuando un visitante genera un HIT, el sistema primero consulta Redis antes de ir a PostgreSQL. Esto es crucial para manejar picos de tráfico.
Nivel 3: PostgreSQL (Persistencia) PostgreSQL almacena dos tablas principales:
- visitors: Tabla de resumen con
visitor_id,fingerprint,user_id(nullable),hit_count, timestamps - visits: Tabla de eventos con todos los HITs, incluyendo JSONB para metadata flexible
4. Estrategia UPSERT para Alta Concurrencia
Para evitar race conditions cuando múltiples HITs del mismo visitante llegan simultáneamente, se usa un UPSERT con ON CONFLICT:
INSERT INTO visitors (visitor_id, fingerprint, hit_count, user_id)
VALUES ($1, $2, 1, $3)
ON CONFLICT (visitor_id) DO UPDATE SET
hit_count = visitors.hit_count + 1,
user_id = COALESCE($3, visitors.user_id),
updated_at = NOW();
Esto garantiza atomicidad y evita conteos duplicados incluso con miles de HITs concurrentes.
Flujo de un HIT de Extremo a Extremo
- Usuario carga página → FingerprintJS genera hash
- POST /visitor → Payload enviado al backend
- Backend valida token → Middleware de autenticación (Bearer token)
- Extracción de IP real → Considera CF-Connecting-IP, X-Forwarded-For
- Geolocalización → Lookup en caché de IPs o llamada a servicio externo
- Lookup de visitor_id → Consulta Redis → Si no existe, consulta PostgreSQL → Si no existe, genera nuevo UUID
- Insert HIT en visits → Registro del evento en PostgreSQL
- UPSERT en visitors → Incrementa hit_count atómicamente
- Actualización de caché → Escribe visitor summary en Redis (TTL 10min)
- Respuesta al cliente → Devuelve visitor_id y hit_count actual
Todo este flujo se completa en 5-15ms en promedio, incluso con millones de HITs diarios.
Casos de Uso Avanzados
1. Linking de Visitantes Anónimos con Usuarios Autenticados
El sistema permite que un visitante inicialmente anónimo (identificado solo por fingerprint) sea vinculado a un user_id cuando se autentica. Esto crea un perfil unificado:
- Fase 1: Visitante navega anónimamente → HITs con visitor_id pero user_id=null
- Fase 2: Visitante inicia sesión → Próximo HIT incluye user_id
- Fase 3: Sistema actualiza visitor record → Todos los HITs históricos ahora están asociados al user_id
Esto es invaluable para:
- Recuperación de carritos abandonados: Enviar email recordatorio basado en productos vistos antes del login
- Recomendaciones personalizadas: Usar comportamiento pre-login para mejorar algoritmos
- Análisis de conversión: Medir el impacto de contenido pre-login en registros posteriores
2. Detección de Comportamiento Fraudulento
Al analizar patrones de HITs, puedes detectar:
- Multiple accounts fraud: Varios user_id desde el mismo fingerprint
- Credential stuffing: Múltiples intentos de login desde diferentes IPs pero mismo fingerprint
- Bot detection: HITs con navegadores sin JavaScript, velocidades de navegación no humanas, o fingerprints inusuales
3. Personalización de Experiencia en Streaming
Plataformas como Netflix o Spotify podrían usar este sistema para:
- Detectar dispositivos compartidos (múltiples user_id desde mismo fingerprint en diferentes momentos)
- Ajustar calidad de streaming según país detectado (ip_country)
- Recomendar contenido basado en URLs visitadas antes de la selección final
4. Optimización de Conversión en Ecommerce
Al rastrear URLs visitadas (almacenadas en cada HIT), puedes:
- Identificar productos más vistos pero con baja conversión
- Detectar puntos de fricción en el checkout (HITs en
/cartpero no en/checkout/success) - Segmentar visitantes por paths de navegación para A/B testing
Diferencias Clave: Fingerprint/HIT vs Google Analytics/Matomo
| Aspecto | Fingerprint/HIT Custom | Google Analytics | Matomo |
|---|---|---|---|
| Propiedad de datos | Total (infraestructura propia) | Configurable (Cloud/Self-hosted) | |
| Granularidad | Cada HIT sin agregación | Agregado en dashboards | Agregado en dashboards |
| Latencia de consulta | < 10ms (desde PostgreSQL) | Segundos a minutos | Segundos a minutos |
| Integración custom | Total (SQL directo, APIs propias) | Limitada por API de Google | Mejor que GA, pero limitada |
| Costo a escala masiva | Infraestructura (predecible) | Analytics 360 (muy costoso) | Infraestructura + licencia opcional |
| GDPR/Privacy | Total control | Problemas de compliance | Mejor control (self-hosted) |
| Machine Learning | Datos directos para modelos propios | Limitado a insights de Google | Limitado |
| Detección de fraude | Tiempo real con reglas custom | No diseñado para esto | No diseñado para esto |
| Trazabilidad user → visitor | Linking explícito en DB | Usa User-ID feature (limitado) | Usa User-ID feature (limitado) |
Beneficios Medibles de la Arquitectura
1. Reducción de Latencia en Decisiones Al tener acceso directo a PostgreSQL con índices optimizados, las consultas como “últimas 100 visitas de este usuario” o “todos los visitantes desde España en las últimas 24h” se ejecutan en milisegundos, permitiendo personalización en tiempo real.
2. Escalabilidad Horizontal La arquitectura puede escalarse horizontalmente añadiendo:
- Más instancias de la API (stateless, balanceo de carga trivial)
- Read replicas de PostgreSQL para consultas analíticas
- Clusters de Redis para caché distribuido
3. Costos Predecibles Con esta arquitectura manejando 100M de HITs/día, los costos típicos serían:
- PostgreSQL (AWS RDS r6g.2xlarge): ~$500/mes
- Redis (ElastiCache r6g.large): ~$200/mes
- API instances (EC2 c6g.xlarge x3): ~$300/mes
- Total: ~$1000/mes vs $150,000/año de Google Analytics 360
4. Trazabilidad Completa para Auditorías Cada HIT se persiste con timestamps precisos, permitiendo reconstruir exactamente qué vio cada visitante en cualquier momento, crucial para compliance y debugging.
Extensiones y Mejoras Futuras
1. Stream Processing con Kafka
Para volúmenes extremos (1000M HITs/día), los HITs podrían enviarse a Kafka topics y procesarse asíncronamente, escribiendo a PostgreSQL en batches y actualizando Redis en tiempo real.
2. Data Warehouse para Analítica Histórica
HITs de más de 30 días podrían archivarse en Redshift o BigQuery para análisis históricos, manteniendo PostgreSQL solo para datos “calientes”.
3. Machine Learning en Tiempo Real
Con acceso directo a HITs, podrías entrenar modelos de:
- Predicción de churn (patrones de navegación que preceden a desuscripción)
- Recomendación de contenido (based on URL patterns)
- Detección de anomalías (comportamiento sospechoso)
4. Dashboard de Analítica Custom
Construir un dashboard en React/Vue que consulte directamente PostgreSQL vía API, ofreciendo métricas personalizadas que Google Analytics no puede proporcionar.
Conclusión
Las estrategias de Fingerprint y HIT Tracking representan un cambio de paradigma para organizaciones que operan a escala masiva y requieren control total sobre sus datos de analítica. Mientras que herramientas como Google Analytics y Matomo son excelentes para casos de uso generales, las arquitecturas de alta concurrencia en sectores como ecommerce, streaming, fintech o gaming demandan soluciones que ofrezcan:
- Latencias por debajo de 10ms para decisiones en tiempo real
- Granularidad completa sin agregación de datos
- Trazabilidad exhaustiva de cada interacción usuario-plataforma
- Escalabilidad ilimitada para manejar picos de tráfico masivos
- Costos predecibles independientes del volumen de eventos
- Privacidad y compliance con control total sobre dónde residen los datos
La arquitectura presentada, basada en FingerprintJS, Go, PostgreSQL y Redis, demuestra que es posible construir sistemas de analítica de clase empresarial sin depender de terceros, con inversiones de infraestructura razonables y rendimientos excepcionales. A medida que las regulaciones de privacidad se endurecen y las expectativas de personalización aumentan, el control directo sobre los datos de visitantes dejará de ser un lujo para convertirse en una necesidad estratégica.
Si tu organización procesa millones de visitas diarias y necesitas tomar decisiones basadas en datos sin comprometer privacidad, rendimiento o costos, el Fingerprint/HIT Tracking no es solo una opción, es el camino a seguir.