Muchas de las empresas y más las llamadas Data Centric pueden tener estrategias de Gobierno del Dato (de sus datos) pero, seguramente con toda probabilidad, no tendrán sus datos democratizados. ¿Qué entendemos por “Democratización de datos”?. Lo miraré de resolver con otra pregunta:
¿Cuántos de los nuevos productos o nuevas releases nacen mal o más tarde de lo previsto porque no se conocen bien las fuentes origen de los datos que requerimos?. Me aventuro y digo que más del 50% de los Proyectos no nacen como es debido por “culpa” de no tener bien identificados nuestras necesidades iniciales. Seguramente daría para otro artículo.
Es por eso que quiero realizar éste post pensando en la Democratización de nuestros datos. El poder localizar de forma correcta, rápida y ágil nuestros datos es vital y, seguramente, garantía de éxito para potenciar cualquiera de nuestros productos, servicios, etc… Antes de entrar con más detalle represento la idea mediante un gráfico, veamos:
En el anterior diagrama podemos ver varias figuras representadas, seguramente tengamos más, algunas que podemos reconocer: bases de datos, tablas, usuarios, Apps, etc… seguidamente tenemos las relaciones, ya que un usuario puede ser “owner” o creador de recursos, puede simplemente explotarlos, una aplicación puede ser consumidora o estar asociada, etc… al final, tendremos un mapa con nuestro ecosistema. Simplemente, con nuestro modelo, podremos ver las relaciones entre nodos, componentes, etc… y así ver quién lo produjo o consumió. No nos olvidemos, pero en éste caso las personas también formamos parte como recursos de datos. Es por eso que en el mapa podremos ver reflejados aquellos empleados que hayan utilizado o posean un recurso de datos determinado y así poder aumentar la eficacia del intercambio de conocimientos.
Con un mero gráfico de nuestro ecosistema podremos darle seguimiento Real al linaje y a la información multifuncional. Los datos son como un proxy para las operaciones más transaccionales de toda Organización. Sin entrar a comentar que, mayormente, las Organizaciones somos como las Tribus, donde la información está totalmente dispersa, segregada y sin indexar.
¿Qué pasa cuando un indivíduo abandona una Organización?
En algunas casos es realmente un problema. Es por eso que confiar plenamente en éste funcionamiento “orgánico” impide totalmente el poder descubrir los datos y, por lo tanto, hace falta desarrollar un sistema autoservido que brinde transparencia a nuestro complejo y a menudo oscuro panorama de datos. Esperando, entonces, que nosotros las personas pasemos a pensar en un origen de datos individual al concepto de un espacio de datos integrado; el espacio de datos presentará una visión holística de los datos y, por lo tanto, proporcionará el contexto necesario para que las personas estemos, simplemente, informadas.
Esto será un total “Next Level” para nuestra Organización y va a suponer un marco de nuevas y mejores prácticas tanto para los datos, como para la privacidad y la seguridad. La idea es poder crear una Plataforma muy simple y abierta para toda la Organización y así poder encontrar muy rápidamente aquellos datos que podamos necesitar para nuestros futuros proyectos. La máxima es romper con los aislamientos tanto de herramientas como de personas o equipos, abrir la Organización y dotarnos de un espacio de datos con contexto global, fácil y que podamos sentirnos confiados acerca de la confiabilidad y relevancia de los mismos.
Entonces, ¿cómo lo podemos crear?. Realmente podemos enfocar de muchas formas su creación, la idea es hacerlo simple e integrado dentro de la Organización, no hace falta construirlo de una forma muy compleja, al contrario, por lo tanto podríamos estar pensando en una base de datos de grafos, ya anteriormente hemos hablado al respecto o bien, utilizar ciertas soluciones que nos podrían dar un punto de salida más avanzado, como por ejemplo: Apache Atlas y Apache Ranger.
Apache Atlas & Apache Ranger
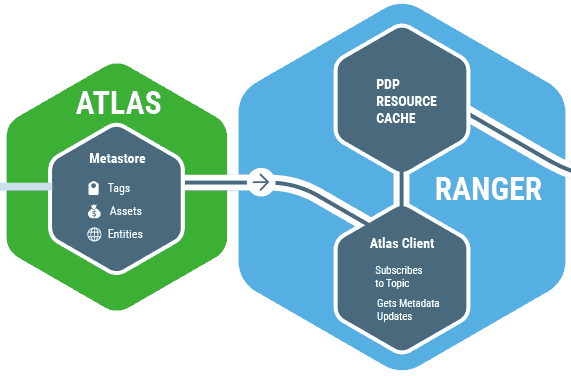
Por ahora lo que queríamos era presentar la idea de la Democratización de datos para que nuestras organizaciones puedan crecer de una forma más sana, más rápida y con una mejor base en la creación y conceptualización de nuevos productos y/o servicios.
Tanto las herramientas de Bi (Business Intelligence), más tradicionales, como las más novedosas y nacidas a partir de la “irrupción” del BigData como son por ejemplo: Tableau, PowerBI, entre muchas otras… han transformado fundamentalmente la forma en que operamos los datos las organizaciones. Los directivos de todas las industrias ahora están utilizando la tecnología de análisis Big Data para una amplia gama de procesos, objetivos y necesidades de gestión. Y las aplicaciones potenciales de las herramientas de BI modernas son prácticamente infinitas, ya que han irradiado en casi todos los aspectos de la gestión operativa y la supervisión estratégica como, se han podido beneficiar de conocimientos más potentes y rápidos.
Pero, muchos estudios, a partir de casos de uso han demostrado que, para la gran mayoría de los adoptantes, los analistas de negocios dedican buena parte de su tiempo a preparar los datos para el análisis, y parece que nunca tienen la información que necesitan. La preparación de datos es un factor crítico, aunque a menudo pasado por alto en el proceso de análisis y debería ser requerimiento obligatorio (mandatory) para poder obtener el máximo valor y, así, extraer lo máximo a las soluciones de análisis y ayudar a las organizaciones a tomar más y mejores decisiones o, como mínimo, más significativas y oportunas.
Druid & Imply.io
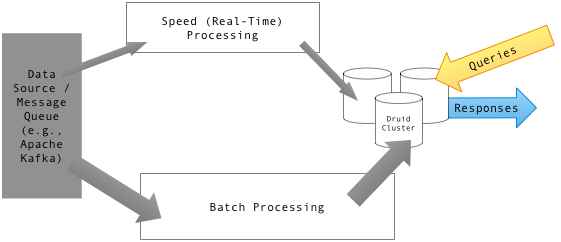
- Druid es un data store de código abierto diseñado para consultas OLAP basadas en streams y eventos.
- Imply.io que es una solución de análisis de alto rendimiento para almacenar, consultar y visualizar datos operativos (fue creado por los creadores de Druid).
NOTA: Una de las claras ventajas de utilizar Imply.io para la visualización de los datos es que dispone de un número importante de conectores, por ejemplo: podremos conectarlo a Kafka para tener analítica en tiempo real de cualquier de nuestros topics.
Druid en Docker
Cómo decíamos anteriormente, Druid es un data store, por lo tanto podremos conectarlo a distintas fuentes de datos para que él vaya generando sus datasources própios. Por ejemplo podemos ver en la imagen siguiente nuestro caso de uso, que hemos conectado una fuente de datos de productos de Banca.
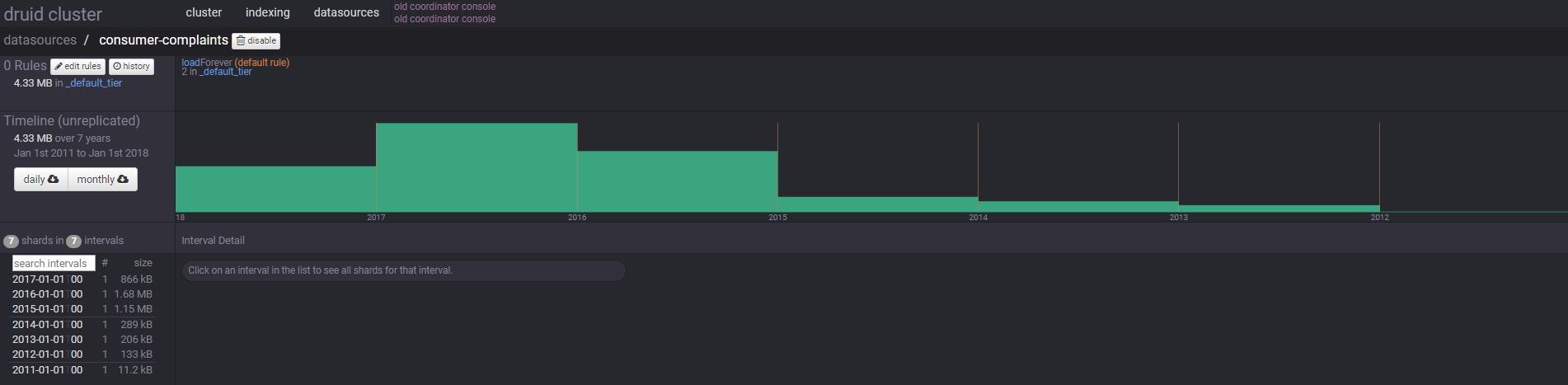
Para poder lanzar Druid podemos hacerlo de forma muy simple y rápida mediante Docker: docker run --name druid -d -p 8082:8082 -p 8081:8081 druidio/example-cluster y mediante navegador podremos acceder a su website de administración: http://localhost:8081.
Imply.io en Docker
Una de las claras ventajas de Imply.io es su simplicidad para crear una visualización, ya sea un Data Cube o bien un Dashboard. Podemos ver en la siguiente imagen la creación de un Data Cube mediante “Drag and Drop”:
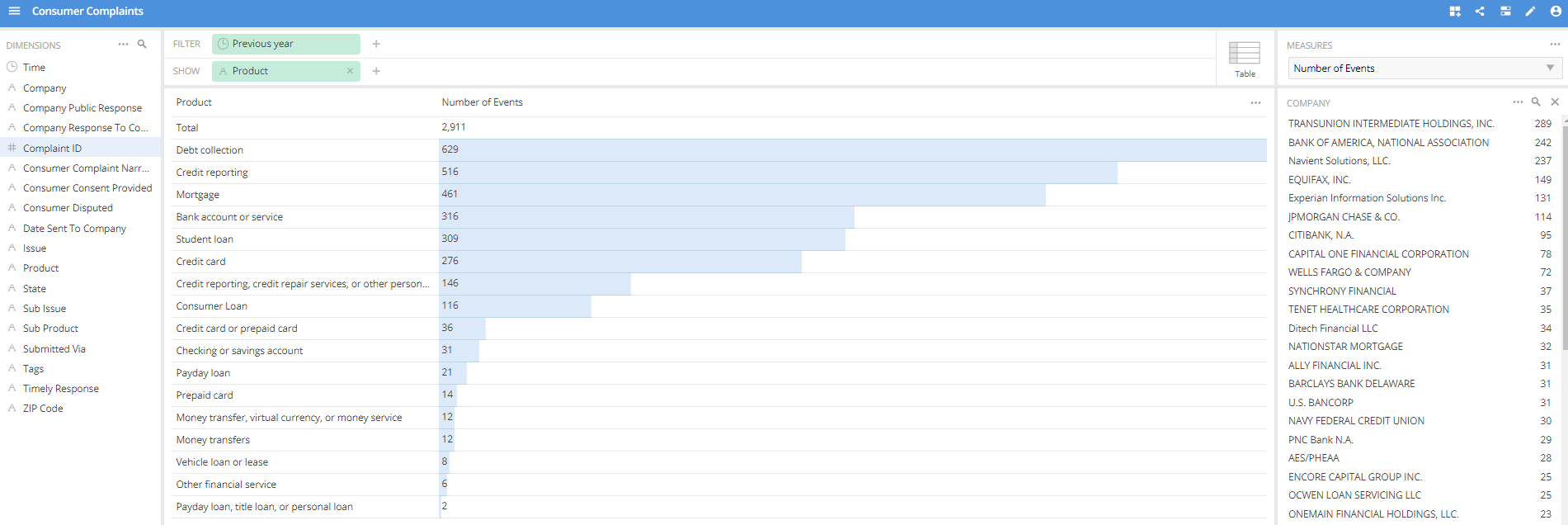
Anteriormente ya hemos visualizado la simplicidad que supone agregar un nuevo Dataset, una vez escogido el orígen, Imply.io agregará un nuevo datasource en Druid y, mediante el supervisor interno que tiene, que hemos parametrizado (opcional) cuando la creación del Dataset, se realizará un procesos de sincronización de datos automáticamente para que cuando creemos nuestros Data Cube o Dashboard puedan tener acceso, casi, en tiempo real a los mismos.
Para poder lanzar Imply.io podemos hacerlo de forma muy simple y rápida mediante Docker: docker run -p 8081-8110:8081-8110 -p 8200:8200 -p 9095:9095 -d --name imply imply/imply y mediante navegador podremos acceder al panel de admin de Imply.io y empezar a crear nuestro pivot: http://localhost:9095
Junto con el docker de Imply.io también desplega Druid, en caso que simplemente queramos hacer una PoC, podemos desplegar sólo éste contenedor y tendremos tanto Druid como Imply.io.