Ya por aquí hemos hablado, y mucho, de #Data-Pipeline o #Data-Streaming. Por ejemplo fue el caso del Banco ING Direct, donde a partir de una Pipeline podían extraer el fruto y conectar su proceso de datos basado en #Real-Time con su reporting o sus bases de datos más operacionales.
También hemos hablado de CQRS, que no es lo mismo que la construcción de Pipeline basadas en #Real-Time sinó, basadas en un método para optimizar escrituras en bases de datos (write) y leerlas (read).
Como podéis ver, hemos hablado ya de casi todos los posibles casos de uso, pero, hoy entraremos en un concepto quizás más general o conceptual. Identificaremos lo que debería ser nuestra estratégia de reteneción de datos y, el proceso de “población” de la misma. Veamos:
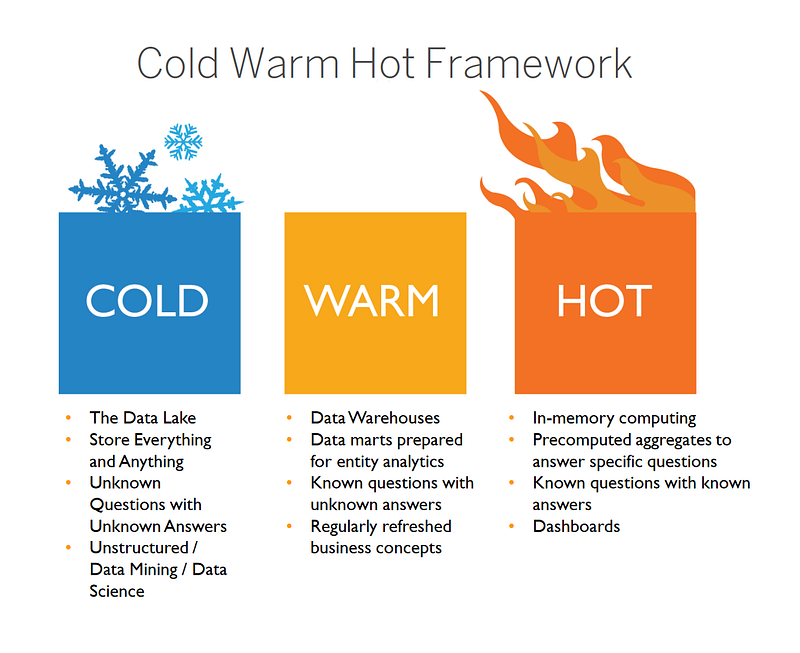
En la anterior imagen tenemos tres ejemplos de retención de datos: COLD, WARM y HOT. Seguramente, según nuestras necesidades, utilizaremos uno u otro, o quizás todos. Depende de cada caso como decíamos.
Cold Storage
El uso de un repositorio basado en “Cold Storage” podría ser cuando usamos una arquitectura de datos basada en #Data-Lake, es decir, nuestro acceso a los datos no es operacional ni tampoco constante. Más bien para sistemas de reporting, BI o agregaciones/transformaciones de datos de procesos basados en colas, etc… no tenemos un acceso continuado al sistema.
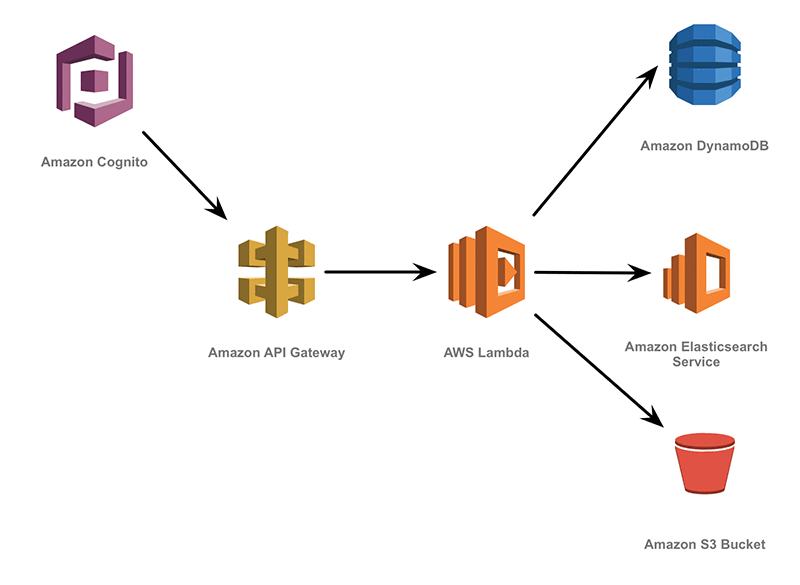
Por ejemplo en la anterior imagen, tenemos un caso basado en un proceso que aglutina los tres ejemplo aquí comentados, centremos ahora por lo que refiere a “Cold Storage”. El proceso estaría basado en un sistema de Amazon S3 Bucket, repositorio, donde podríamos lanzar procesos para la recolección de datos, éste no sería un proceso constante, sinó más bien procesos “Batch” o mediante “COPY” los cuales, como decíamos, recuperarían la información, la podrían agregar o transformar, categorizarla, etc… hacia otro “repositorio” de datos más cercano al operacional como por ejemplo: AWS Redshift. Hablaremos en breve con más detalle.
También en nuestro #Data-Lake podríamos lanzar procesos de Data Mining o de Data Science, sería seguramente, el caso ideal para poder afrontar procesos de #Machine-Learning.
Warm Storage
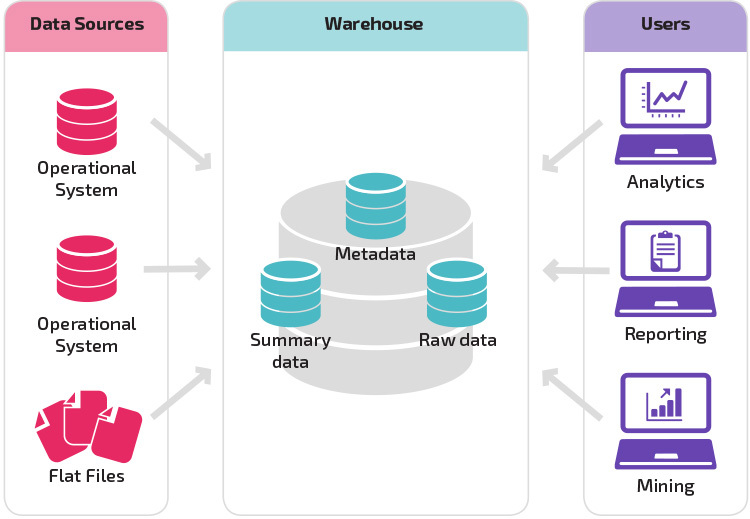
Por lo que refiere a un acceso a los datos más intermédio, o “Warm Storage”, estaríamos hablando de sistemas de Datawarehousing, como AWS Redshift. Redshift jugaría un papel muy importante. No olvidemos que ya en el anterior proceso hemos estructura procesos de extracción de datos de nuestro “#Data-Lake” hacia Redshift. Por lo tanto: ya tenemos los datos disponibles.
Estamos hablando de tener seguramente distintos #Data-Marts, ya totalmente preparados con datos ya anteriormente trabajados y que tienen una función concreta, sea para reporting, sea para cumplir con un requerimiento de negocio para un acceso operacional desde una aplicación, etc… estamos hablando de datos más estructurados y más accesibles a un público “general”.
Hot Storage
Cuando hablamos de acceso a datos “Hot Storage”, nos estamos refiriendo a datos casi basados en memoria computacional, de unas necesidades inmediatas de acceso y, en muchas ocasiones, pre-configurados con anterioridad, guardando el cálculo, agregación, transformación, etc… que facilitan tanto el acceso como el servicio al mismo.
Por ejemplo hablamos de Elasticsearch, Redis, etc… “bases de datos” basadas en memoria y que nos permiten un acceso al dato muy eficiente y muy rápido.
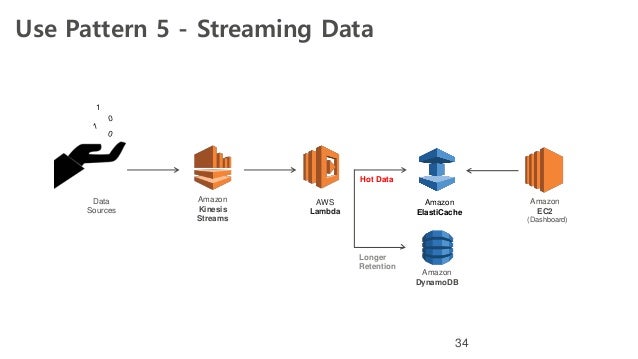
Seguramente el sistema podría completarse de una Base de datos NoSQL, como AWS DynamoDB o MongoDB, para poder reconstruir sus Índices en caso de necesidad, pero, depende de cada caso.
Review
Pues bien, aquí hemos querido plantear distintos escenarios y como decíamos, quizás, por nuestras necesidades no hace falta montar todos ellos, sinó uno o dos. Pero sin duda alguna merece la pena poder pararse y determinar cual debería ser nuestra estrategia de acceso a los datos, que retención merecen, la seguridad de acceso, etc… en definitiva no estamos hablando de un tema menor y más por ejemplo con la entrada de normativas como la GDPR, que también hemos hablado por aquí.
Autor: Joakim Vivas