El 18 de septiembre de 2025, Eric X. Yu, presidente rotatorio de Huawei, subió al escenario en Shanghai y rompió años de silencio absoluto. Lo que reveló no fue simplemente una presentación de productos, fue la evidencia irrefutable de que el monopolio estadounidense en inteligencia artificial avanzada había terminado. Y lo más perturbador: nadie en Silicon Valley lo vio venir.

En este análisis técnico profundo, diseccionaremos cómo una empresa sancionada, sin acceso a procesos de fabricación por debajo de 7nm, desarrolló infraestructura de IA que supera a Nvidia por 6.7x en potencia de cómputo y a XAI Colossus de Elon Musk por 1.3x, todo mientras democratizaba su stack completo mediante open source.
El Contexto Geopolítico: Mayo 2019 - La Sentencia de Muerte que Falló
En mayo de 2019, el gobierno estadounidense ejecutó su arma más devastadora: cortó el acceso de Huawei a semiconductores avanzados fabricados por TSMC usando procesos de 7nm o inferiores. La lógica era simple y brutal:
- Sin acceso a chips de vanguardia → Sin capacidad de competir en IA
- Sin IA avanzada → Sin relevancia en el mercado tecnológico del futuro
- Sin relevancia → Colapso gradual de Huawei como amenaza estratégica
Era una sentencia de muerte tecnológica. O eso pensaban en Washington.
El Error de Cálculo Fundamental
Las sanciones asumían que la única ruta hacia la supercomputación de IA era seguir la estrategia de Nvidia: chips individuales cada vez más potentes. Mientras Nvidia invertía miles de millones en procesos de 5nm, 3nm y eventualmente 2nm, Huawei estaría congelada en tecnología obsoleta. Pero Huawei hizo algo inesperado: cambió la pregunta. En lugar de obsesionarse con “¿cómo fabricamos el chip más rápido?”, preguntaron:
¿Qué pasa si en lugar de tener a Usain Bolt corriendo solo, coordinamos perfectamente a un ejército entero de corredores buenos trabajando en perfecta sincronía?
Esta filosofía arquitectónica no era nueva en teoría, pero implementarla a escala masiva con eficiencia superior a sistemas basados en GPUs de última generación era considerado técnicamente imposible.
Unified Bus: La Innovación que Cambió Todo
Durante seis años, mientras el mundo asumía que Huawei estaba en problemas, sus mejores ingenieros estaban resolviendo silenciosamente uno de los desafíos más complejos de la computación distribuida: el problema de la latencia acumulativa en sistemas masivamente paralelos.
El Problema Técnico
Cuando conectas miles de aceleradores de IA, cada milisegundo de latencia se multiplica. Es como el juego del teléfono descompuesto a escala industrial:
- Cada capa de comunicación introduce errores
- Cada salto entre chips añade latencia
- A escala masiva (10,000+ procesadores), estos retrasos normalmente colapsan el sistema
Las soluciones tradicionales usan protocolos como NVLink de Nvidia o Infinity Fabric de AMD, diseñados para interconexiones de corto alcance (decenas de centímetros) con latencias del orden de nanosegundos.
La Solución: Unified Bus
Huawei tuvo que reinventar completamente la interconexión desde los componentes ópticos hasta los chips de interconexión. El resultado:
- Confiabilidad 100x superior a estándares previos
- Rango de interconexión extendido a +200 metros
- Combinación de confiabilidad del cobre con alcance de fibra óptica
Esto significa que puedes distribuir físicamente 10,000+ chips Ascend en múltiples gabinetes separados por decenas de metros y hacer que funcionen como una sola computadora coherente, con latencias lo suficientemente bajas para entrenamiento de modelos de lenguaje a gran escala. Comparación con NVLink de Nvidia
| Característica | Nvidia NVLink 4.0 | Huawei Unified Bus |
|---|---|---|
| Alcance máximo | ~2 metros | +200 metros |
| Confiabilidad (MTBF) | Baseline100x baseline | |
| Topología óptima | Malla densa (corto alcance) | Distribuida (largo alcance) |
| Escalabilidad | Limitada por alcance físico | Escalable a datacenter completo |
La ventaja arquitectónica es fundamental: mientras Nvidia requiere agrupar GPUs densamente en racks contiguos (con todos los desafíos térmicos y de energía que eso implica), Huawei puede distribuir carga computacional a través de un datacenter entero, optimizando refrigeración, redundancia y costo.
Hoja de Ruta Ascend: Del 950 al 970 (2026-2028)
Eric Hsu no solo anunció productos, reveló completamente la estrategia de tres años de Huawei, algo sin precedentes para una empresa china en un entorno geopolítico tan hostil.
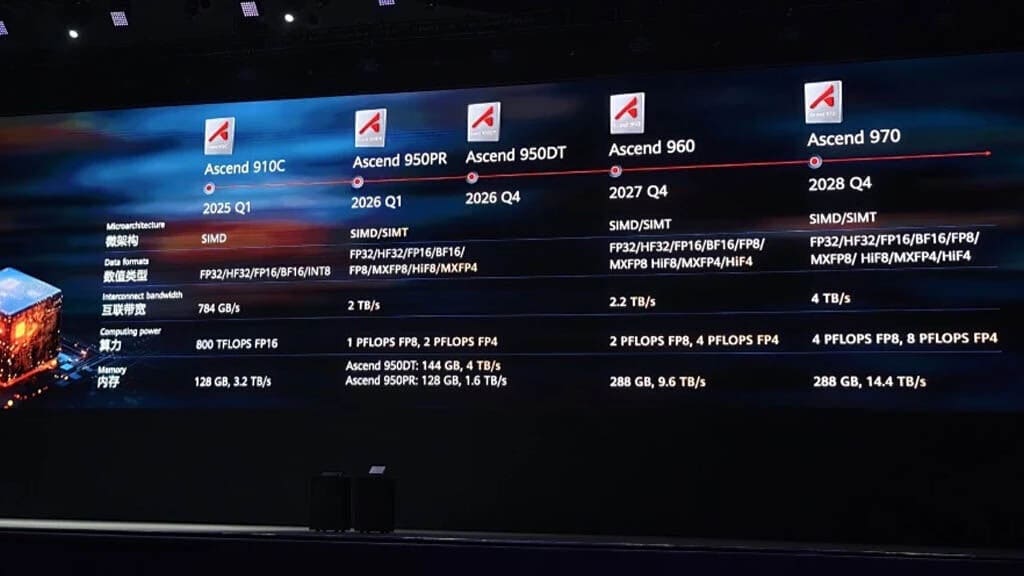
Ascend 950 (2026)
Variantes:
- 950 PR (Processing): Optimizado para inferencia
- 950 DT (Data Training): Optimizado para entrenamiento
Especificaciones clave del 950 DT:
- Memoria: 128 GB HBM (High Bandwidth Memory)
- Ancho de banda: 1.6 TB/s (PR) | 4 TB/s (DT) -Proceso de fabricación: Presumiblemente 7nm (SMIC)
El Detalle Crítico: HBM Autóctono
Hasta 2024, la memoria HBM era monopolio de SK Hynix (Corea del Sur) y Samsung, y estaba sujeta a restricciones de exportación a China. El anuncio de Huawei de 128 GB de HBM desarrollado internamente es devastador por dos razones:
Elimina el cuello de botella más crítico de los aceleradores de IA modernos Demuestra madurez en la cadena de suministro china para componentes considerados imposibles de replicar
Ascend 960 (Q4 2027)
- 2x potencia de cómputo vs 950
- 2x memoria vs 950
- 2x capacidad de interconexión vs 950
- Introducción de Hive 4: Formato de precisión de 4 bits propietario
¿Por qué Hive 4 Importa?
Los formatos de baja precisión (FP8, FP4) son críticos para eficiencia en inferencia. GPT-4, Llama 3 y otros LLMs modernos usan cuantización agresiva para reducir costos. Huawei afirma que Hive 4 entrega mayor precisión que FP4 estándar, lo que significa:
- Menos degradación de calidad al cuantizar modelos
- Costos de inferencia más bajos sin sacrificar rendimiento
- Ventaja competitiva en deployment de modelos a escala masiva
Ascend 970 (Q4 2028)
- 2x potencia FP4/FP8 vs 960
- 2x ancho de banda de interconexión vs 960
- 1.5x ancho de banda de memoria vs 960
Si Huawei cumple esta hoja de ruta, para finales de 2028 estará igualando o superando el ritmo de innovación de Nvidia, que históricamente lanzaba nuevas arquitecturas cada 18-24 meses.
Los Sistemas que Cambian Todo: Atlas 950 SuperPod y SuperCluster
Los chips son impresionantes, pero los sistemas que Huawei construirá con ellos son lo que realmente debería preocupar a la competencia.

Atlas 950 SuperPod (Finales 2026)
Configuración:
- 8,192 chips Ascend 950 DT
- 160 gabinetes
- 8 exaflops (FP8) | 16 exaflops (FP4)
Comparación con Nvidia:
- 56.8x más procesadores que el sistema NVL-144 de Nvidia planeado para 2026
- 6.7x más potencia de cómputo que NVL-144
Análisis Crítico: ¿Es Esto Posible?
Hay escepticismo razonable. ¿Cómo puede un chip fabricado en 7nm (significativamente menos eficiente que 3nm de TSMC) entregar más potencia de cómputo agregada?
La respuesta está en tres factores:
- Eficiencia de interconexión: Unified Bus elimina overhead de comunicación
- Densidad de integración: Huawei puede empaquetar más chips por gabinete sin colapsar por calor
- Software optimizado: El stack Cann (más sobre esto abajo) está diseñado para extraer máxima eficiencia del hardware
Atlas 950 SuperCluster (Finales 2026)
Configuración:
- 64 SuperPods
- 520,000+ chips Ascend 950 DT
- 10,000+ gabinetes
- 524 exaflops (FP8)
Comparación con XAI Colossus:
- 2.5x más procesadores que Colossus de Elon Musk
- 1.3x más potencia de cómputo que Colossus
Este sistema sería el clúster de computación más grande del mundo, superando al actual líder (Colossus, con ~200,000 GPUs H100).
Atlas 960 SuperCluster (2027)
- 1,000,000+ procesadores
- 2 zettaflops (FP8) | 4 zettaflops (FP4)
Para contexto, 2 zettaflops = 2,000 exaflops. El supercomputador más rápido del mundo en 2024 (Frontier, Oak Ridge) alcanza 1.2 exaflops. Huawei está hablando de sistemas 1,666x más poderosos en solo tres años.
DeepSeek R1: La Validación en el Mundo Real
Toda esta infraestructura sería teórica si no hubiera pruebas de que funciona. En enero de 2025, una startup china llamada DeepSeek lanzó algo que envió ondas de choque a través de Silicon Valley: DeepSeek R1: El Modelo que Costó $294,000
Resultados en benchmarks:
- AME 2024: 79.8% (comparable a GPT-4)
- Codeforces: 96.3% (superior a la mayoría de modelos comerciales)
- MATH500: 97.3% (state-of-the-art en razonamiento matemático)
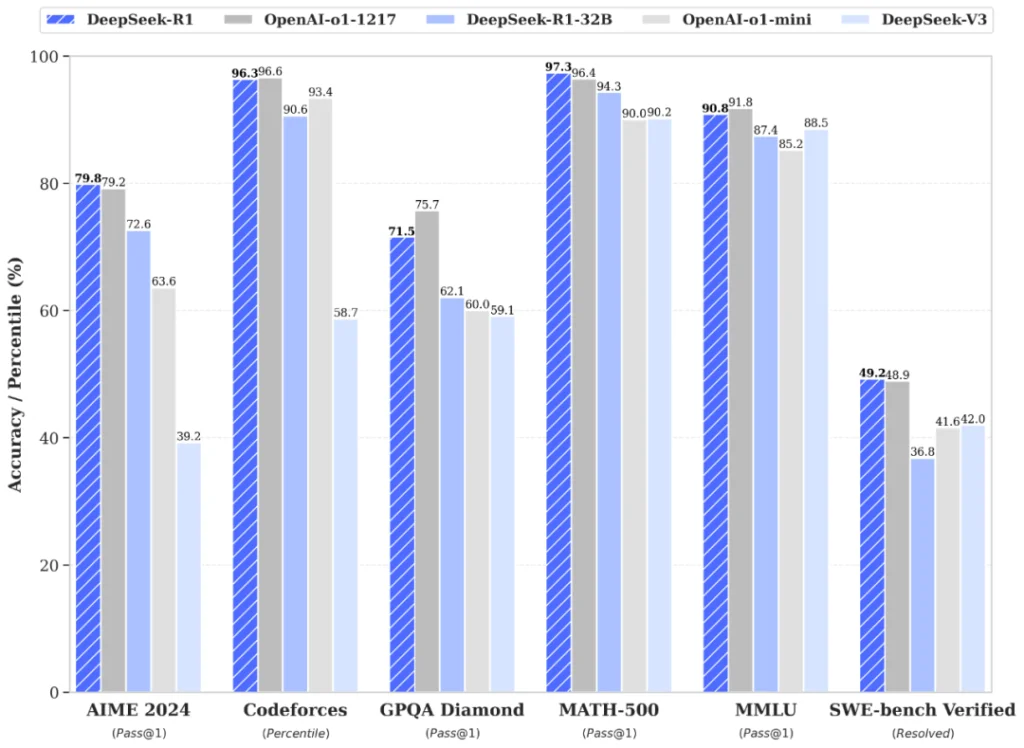
Estos números por sí solos son impresionantes. Pero el detalle que hizo entrar en pánico a OpenAI, Google y Anthropic:
DeepSeek entrenó este modelo usando solo $294,000 en cómputo.
Para contexto:
- GPT-4: Estimado en $100-200 millones
- Llama 3: Estimado en $50-100 millones
- Claude 3: Sin cifras públicas, pero orden similar
¿Cómo es Posible?
Dos innovaciones clave:
1. Aprendizaje por Refuerzo Puro
DeepSeek desarrolló técnicas que eliminan la necesidad de enormes datasets etiquetados por humanos (RLHF tradicional). En lugar de:
Datos anotados → Modelo supervisado → Fine-tuning con RLHF
Usaron:
Recompensa sintética → Entrenamiento por refuerzo directo
Esto reduce costos de datos de millones a miles de dólares.
2. Chips Ascend de Huawei
DeepSeek entrenó R1 usando chips Ascend 910B, la generación anterior al 950. Esto significa:
- Infraestructura china completamente independiente
- Sin necesidad de GPUs Nvidia (que están sancionadas)
- Demostración práctica de que Ascend funciona para entrenar modelos frontier
El Impacto: $600,000 Millones Borrados de Nvidia
Cuando DeepSeek lanzó R1 el 20 de enero de 2025, Nvidia perdió $589,000 millones en capitalización de mercado en una semana. No era pánico irracional, era el mercado reaccionando a una realidad nueva:
El monopolio de Nvidia en IA de vanguardia había terminado.
La Magia de la Arquitectura Distribuida
Imagina dos escenarios:
Escenario Nvidia:
- 1,000 GPUs H100
- Interconectadas con NVLink
- Rendimiento teórico: 1,000 unidades
- Rendimiento real (con overhead de comunicación): ~850 unidades
Escenario Huawei:
- 5,000 chips Ascend (cada uno ~33% de H100)
- Interconectados con Unified Bus
- Rendimiento teórico: 1,650 unidades
- Rendimiento real (overhead mínimo): ~1,550 unidades
Resultado: Huawei gana por ~82% a pesar de tener chips individuales más lentos.
La Jugada Estratégica: Open Source Total
El 31 de diciembre de 2024, Huawei ejecutó la jugada más brillante de todas: anunció que haría completamente open source su stack de software de IA. Lo que Liberaron:
Cann (Compute Architecture for Neural Networks)
El equivalente a CUDA de Nvidia, pero open source. Cann incluye:
- Compiladores optimizados para Ascend
- Kernels de operaciones de álgebra lineal
- Frameworks de entrenamiento distribuido
- Herramientas de profiling y debugging
MindSpore y Herramientas MindSeries
Framework de deep learning comparable a PyTorch o TensorFlow, pero optimizado nativamente para Ascend.
Modelos de Fundación Pangu
Modelos pre-entrenados (LLMs, modelos de visión, multimodales) que desarrolladores pueden fine-tunear para sus aplicaciones.
¿Por Qué Regalar Todo?
En superficie, no tiene sentido. Nvidia mantiene CUDA cerrado y cobra miles de millones en licencias. ¿Por qué Huawei regalaría su ventaja competitiva? La respuesta es guerra de ecosistemas. La Lógica Implacable.
Estrategia Nvidia:
- CUDA es propietario
- Solo funciona en GPUs Nvidia
- Lock-in total: Una vez que aprendes CUDA, cambiar a AMD/Intel es prohibitivamente costoso
Contraofensiva Huawei:
- Cann es open source
- Cualquier desarrollador puede aprender sin costo
- Cada aplicación construida sobre Cann es una razón para comprar chips Ascend
- La barrera para adopción es cero
Es exactamente la estrategia que usó Linux para destruir Unix propietario o Android para dominar iOS. No ganas por tener el mejor producto cerrado, ganas por construir el ecosistema abierto más grande.
El 16 de Septiembre: China Prohíbe Nvidia
Dos días antes del anuncio de Huawei, China ejecutó su contraataque más agresivo: prohibió a todas sus empresas tecnológicas comprar chips Nvidia. Según el Financial Times, Beijing había determinado que:
Los procesadores de IA chinos ya igualan o superan las capacidades de los productos Nvidia que caen bajo restricciones de exportación estadounidenses.
No era bravuconería. Con DeepSeek R1 demostrando que chips Ascend podían entrenar modelos competitivos con GPT-4, la evaluación tenía sentido.
El Impacto en Nvidia
China representaba hasta el 17% de los ingresos totales de Nvidia. La prohibición eliminaba efectivamente lo que quedaba de un mercado de ~$10,000-15,000 millones anuales. Pero el daño real no era financiero inmediato, era estratégico a largo plazo:
- Desarrolladores chinos ahora aprenden Cann en lugar de CUDA
- Startups chinas construyen sobre MindSpore en lugar de PyTorch
- Universidades chinas investigan sobre arquitecturas Ascend
Cada uno de esos desarrolladores, startups y académicos es una inversión en el futuro del ecosistema Huawei, y una pérdida permanente para Nvidia.

El problema de [Nvidia](https://www.nvidia.com/) no es que Huawei tenga chips mejores (no los tiene, individualmente). El problema es que Huawei cambió el juego. Es como si estuvieras compitiendo en una carrera de velocidad y tu oponente decidiera que la carrera es de relevos. Puedes ser el corredor más rápido del mundo, pero si tu oponente tiene mejor coordinación de equipo, pierdes.
Opciones de Nvidia:
- Desarrollar interconexión de largo alcance: Requiere años de R&D y probablemente patentes de Huawei
- Bajar precios agresivamente: Erosiona márgenes sin resolver el problema arquitectónico
- Apostar todo a IA edge: Cambiar foco a inferencia en dispositivos donde chips monolíticos aún tienen ventaja
Conclusión: El Fin del Monopolio
Lo que acaba de ocurrir no es simplemente el lanzamiento de nuevos productos. Es el fin de una era donde la innovación tecnológica más avanzada estaba concentrada en un puñado de empresas estadounidenses. Por primera vez en décadas, existe una alternativa real, viable y en muchos aspectos superior al stack tecnológico occidental:
- Hardware: Ascend SuperClusters superan a lo mejor de Nvidia en potencia agregada
- Software: Cann + MindSpore open source vs CUDA propietario
- Modelos: DeepSeek R1 y Qwen 3 Omni comparables a GPT-4 y Gemini, pero gratuitos
- Costo: Entrenar modelos frontier por $294K vs $100M+

Las sanciones de 2019 que se suponía destruirían a Huawei terminaron acelerando el desarrollo de una industria tecnológica china completamente independiente. Es la ironía geopolítica más grande de la década. La pregunta ya no es si China alcanzará a Occidente en IA. La pregunta es qué tan rápido Occidente reaccionará al hecho de que ya ha sido alcanzado.