Cuando construyes un sistema de IA a gran escala, en realidad estás combinando diferentes patrones de diseño agéntico. Cada uno tiene su propia etapa, método de construcción, salida y evaluación. Si damos un paso atrás y agrupamos estos patrones, podemos descomponerlos en 17 arquitecturas de alto nivel que capturan las principales formas que los sistemas agénticos pueden adoptar en la práctica.
En este artículo, exploraremos cada uno de estos patrones de arquitectura, analizaremos su aplicación práctica, y veremos cómo herramientas empresariales como Glean están implementando algunos de estos conceptos para construir sistemas de IA que realmente funcionan en entornos de producción.
¿Qué son los Sistemas Agénticos de IA?
Antes de sumergirnos en los patrones, es importante entender qué hace que un sistema de IA sea “agéntico”. A diferencia de los modelos de lenguaje tradicionales que simplemente responden a prompts, los agentes de IA son sistemas que:
- Planifican: Descomponen problemas complejos en pasos manejables
- Actúan: Utilizan herramientas y APIs para interactuar con el mundo real
- Aprenden: Mejoran su rendimiento basándose en feedback y resultados previos
- Razonan: Evalúan múltiples caminos antes de tomar decisiones
- Colaboran: Trabajan con otros agentes especializados para resolver problemas complejos
Esta capacidad de autonomía y razonamiento es lo que distingue a los sistemas agénticos de las simples aplicaciones de IA conversacional.
Los 17 Patrones de Arquitecturas Agénticas
1. Reflection (Reflexión)
El patrón de Reflexión es probablemente el más fundamental y común en los workflows agénticos. Se trata de dar al agente la capacidad de dar un paso atrás, evaluar su propio trabajo y mejorarlo iterativamente.
Cómo funciona:
- Generate: El agente produce una solución inicial o borrador
- Critique: El agente se convierte en su propio crítico, analizando el borrador en busca de fallos
- Refine: Basándose en su propia crítica, genera una versión mejorada
Caso de uso práctico: Imagina un agente generando código Python para ordenar una lista de números. En la primera iteración, produce una solución con bubble sort, simple pero ineficiente con complejidad O(n²). Al autoevaluarse, detecta el problema de rendimiento. En la iteración refinada, genera una solución usando quicksort con complejidad O(n log n), maneja casos edge como listas vacías, y sigue las convenciones PEP 8.
Ventaja clave: Este patrón es crítico en cualquier etapa donde la calidad del output es fundamental, como generación de código complejo, reportes técnicos detallados, o cualquier tarea donde una primera versión simplemente no es suficiente.
2. Tool Using (Uso de Herramientas)
El patrón de Uso de Herramientas actúa como puente entre el razonamiento interno del agente y datos del mundo real. Sin acceso a herramientas externas, un LLM está limitado a sus parámetros pre-entrenados: puede razonar, pero no puede consultar información nueva ni interactuar con sistemas externos.
Cómo funciona:
- Receive Query: El agente recibe una consulta del usuario
- Decision: Analiza si necesita una herramienta para responder con precisión
- Action: Si es necesario, formula una llamada a la herramienta con los argumentos correctos
- Observation: Recibe el resultado de la herramienta
- Synthesis: Combina el output de la herramienta con su razonamiento para generar la respuesta final
Caso de uso práctico: Un usuario pregunta: “¿Cuál es el precio actual del Bitcoin y cuáles han sido las principales noticias que han afectado su valor esta semana?”. El agente reconoce que necesita información actualizada en tiempo real, ejecuta una búsqueda web (usando una herramienta como Tavily Search), recibe artículos recientes y datos de mercado, y sintetiza una respuesta basada en información actual y no en datos desactualizados de su entrenamiento.
Ventaja clave: Este patrón es fundamental para cualquier sistema de IA en producción. Ya sea un bot de soporte consultando estados de pedidos, un agente financiero consultando precios de acciones en tiempo real, o un asistente personal accediendo a calendarios, el uso de herramientas es lo que convierte a un LLM estático en un agente dinámico.
3. ReAct (Reason + Act)
ReAct lleva el uso de herramientas un paso más allá al crear un loop de razonamiento. En lugar de una llamada única a una herramienta, el agente puede razonar sobre el resultado, decidir qué hacer a continuación, y continuar este ciclo hasta resolver completamente el problema.
Cómo funciona:
- Receive Goal: Se le da al agente una tarea compleja que no se puede resolver en un solo paso
- Think (Reason): El agente genera un pensamiento: “Para responder esto, primero necesito encontrar X”
- Act: Basándose en ese pensamiento, ejecuta una acción (como llamar a una herramienta de búsqueda)
- Observe: Obtiene el resultado
- Repeat: Toma esa nueva información, razona de nuevo (“Ahora que tengo X, necesito encontrar Y”), y continúa el loop
Caso de uso práctico: Pregunta: “¿Quién es el CEO actual de la compañía matriz de Instagram y cuántos usuarios activos mensuales tiene la plataforma actualmente?”
Un agente simple fallaría. Un agente ReAct razona paso a paso:
- Thought 1: “Primero necesito identificar qué compañía es la matriz de Instagram”
- Action 1: Búsqueda web → Obtiene “Meta Platforms”
- Thought 2: “Ahora necesito el CEO de Meta Platforms”
- Action 2: Búsqueda web → Obtiene “Mark Zuckerberg”
- Thought 3: “Finalmente, necesito los usuarios activos mensuales actuales de Instagram”
- Action 3: Búsqueda web → Obtiene estadísticas de usuarios actuales
Ventaja clave: ReAct es tu patrón por defecto para cualquier tarea que requiera razonamiento multi-hop: investigación compleja, análisis de datos con múltiples fuentes, o resolución de problemas que requieren descubrimiento progresivo.
4. Planning (Planificación)
Mientras que ReAct explora un problema de forma reactiva, el patrón de Planning introduce previsión. En lugar de reaccionar paso a paso, un agente de planificación primero crea un “mapa de batalla” completo antes de tomar cualquier acción.
Cómo funciona:
- Receive Goal: El agente recibe una tarea compleja
- Plan: Un componente “Planner” analiza el objetivo y genera una lista ordenada de sub-tareas
- Execute: Un componente “Executor” lleva a cabo cada sub-tarea en secuencia
- Synthesize: Un componente final ensambla los resultados en una respuesta coherente
Caso de uso práctico: Tarea: “Encuentra el PIB per cápita de España, Portugal e Italia, y calcula el promedio de los tres países”.
Un agente de planificación primero genera el plan completo:
Plan:
1. web_search('PIB per cápita España actual')
2. web_search('PIB per cápita Portugal actual')
3. web_search('PIB per cápita Italia actual')
4. Calcular el promedio de los tres valores
Luego ejecuta metodológicamente cada paso.
Ventaja clave: Planning es tu patrón cuando el camino de solución es predecible: pipelines de procesamiento de datos, generación de reportes, workflows estructurados. Aporta previsibilidad y eficiencia, haciendo el comportamiento del agente más fácil de trazar y depurar.
5. PEV (Planner-Executor-Verifier)
El patrón PEV es una evolución del Planning que añade una capa crítica de control de calidad y auto-corrección. Mientras que un planificador estándar asume que todo funcionará bien, PEV se prepara para el fracaso.
Cómo funciona:
- Plan: Un agente “Planner” crea una secuencia de pasos
- Execute: Un agente “Executor” ejecuta el siguiente paso del plan
- Verify: Un agente “Verifier” examina el output de la herramienta, comprobando errores, relevancia y validez
- Route & Iterate: Basándose en el juicio del Verifier:
- Si el paso tuvo éxito, continúa al siguiente paso
- Si falló, vuelve al Planner para crear un nuevo plan, ahora consciente del fallo
Caso de uso práctico: Consulta: “¿Cuál fue la inversión en energías renovables de Google en su último año fiscal y cuál fue su huella de carbono? Calcula la inversión por tonelada de CO2”.
Si la herramienta de búsqueda falla al obtener los datos de huella de carbono (API caída, query mal formada, etc.), un Planner simple pasaría el error. PEV lo detecta:
- Verifier: “Este output es un mensaje de error, no datos válidos”
- Router: Envía de vuelta al Planner
- Planner: Reformula la consulta (“emisiones de CO2 de Google a nivel global”)
- Executor: Prueba de nuevo con la nueva query
- Success: Obtiene los datos y completa la tarea
Ventaja clave: PEV es esencial para construir workflows robustos y confiables. Lo usas donde un agente interactúa con herramientas externas potencialmente no confiables: APIs públicas, web scraping, servicios de terceros.
6. Tree-of-Thoughts (ToT)
El patrón Tree-of-Thoughts cambia de razonamiento lineal a exploración de múltiples caminos. En lugar de generar una única línea de razonamiento, un agente ToT explora varias rutas simultáneamente, evalúa cada una, descarta las malas, y continúa explorando las ramas más prometedoras.
Cómo funciona:
- Decomposition: El problema se descompone en pasos o “pensamientos”
- Thought Generation: Para el estado actual, el agente genera múltiples posibles siguientes pasos
- State Evaluation: Cada nuevo paso potencial es evaluado por una función crítica
- Pruning & Expansion: El agente “poda” las ramas malas y continúa desde las buenas
- Solution: Esto continúa hasta que una rama alcanza el objetivo final
Caso de uso práctico: El clásico problema de las Torres de Hanoi con 4 discos. Un agente Chain-of-Thought simple podría fallar al no encontrar la secuencia óptima. Un agente ToT descubre la solución mediante búsqueda sistemática:
- Explora mover disco grande primero → Estado inválido (viola reglas del juego)
- Explora mover disco pequeño a torre intermedia → Estado válido ✓
- Desde aquí, explora diferentes secuencias de movimientos
- Poda movimientos que violan restricciones o crean ciclos
- Continúa hasta encontrar la solución óptima de 15 pasos
Ventaja clave: ToT es tu patrón para problemas que requieren alta confiabilidad y tienen múltiples caminos de solución: planificación de rutas, scheduling complejo, puzzles lógicos, o cualquier tarea donde necesitas garantías de que la solución es válida.
7. Multi-Agent Systems (Sistemas Multi-Agente)
En lugar de construir un super-agente que hace todo, los Sistemas Multi-Agente usan un equipo de especialistas. Cada agente se enfoca en su propio dominio, como expertos humanos, no pedirías a un data scientist que escriba copy de marketing.
Cómo funciona:
- Decomposition: Una tarea compleja se descompone en sub-tareas
- Role Definition: Cada sub-tarea se asigna a un agente especialista basándose en su rol
- Collaboration: Los agentes ejecutan sus tareas, pasando sus hallazgos entre ellos o a un manager central
- Synthesis: Un agente “manager” final recopila los outputs de los especialistas y ensambla la respuesta consolidada
Caso de uso práctico: Tarea: “Crea un reporte de análisis de mercado breve pero completo para Tesla (TSLA)”.
Equipo de especialistas:
- News Analyst: Analiza noticias recientes y sentimiento del mercado
- Technical Analyst: Examina gráficos de precios, tendencias técnicas
- Financial Analyst: Analiza finanzas, métricas de valoración
- Report Writer: Actúa como manager, sintetizando todo en un reporte coherente
El output es estructurado, con secciones claras y distintas para cada área de análisis, cada una con lenguaje específico del dominio y mayor profundidad.
Ventaja clave: Para tareas complejas que pueden descomponerse, un equipo de especialistas casi siempre superará a un generalista único. Es como tener un equipo de consultores expertos trabajando en paralelo.
8. Meta-Controller (Meta-Controlador)
El patrón Meta-Controller introduce un dispatcher inteligente. En lugar de ejecutar todos los especialistas en secuencia (desperdiciando tiempo y dinero), el meta-controlador analiza la consulta del usuario y la enruta al especialista correcto.
Cómo funciona:
- Receive Input: El sistema recibe una consulta del usuario
- Meta-Controller Analysis: El agente Meta-Controller examina la consulta para entender su intención
- Dispatch to Specialist: Basándose en su análisis, selecciona el mejor especialista
- Execute Task: El especialista elegido ejecuta y genera un resultado
- Return Result: El resultado se devuelve directamente al usuario
Caso de uso práctico: Especialistas disponibles:
- Generalist: Maneja conversación casual, saludos
- Researcher: Responde preguntas que requieren información actualizada de la web
- Coder: Escribe código Python basándose en especificaciones
Queries de prueba:
- “Hola, ¿cómo estás?” → Ruteado a Generalist
- “¿Cuáles fueron los últimos resultados financieros de Microsoft?” → Ruteado a Researcher
- “¿Puedes escribirme una función Python para validar una dirección de email?” → Ruteado a Coder
Ventaja clave: El Meta-Controller es el sistema nervioso central de sistemas RAG o agénticos complejos. Es la puerta frontal que rutea consultas al departamento correcto, haciendo que sistemas de IA sean escalables y fáciles de mantener.
9. Blackboard (Pizarra)
Mientras que el Multi-Agente usa secuencias rígidas, la arquitectura Blackboard permite un workflow dinámico y oportunista. Funciona como expertos humanos resolviendo problemas alrededor de una pizarra compartida: un líder mira la pizarra y decide quién debería contribuir a continuación.
Cómo funciona:
- Shared Memory (The Blackboard): Un almacén de datos central que contiene el estado actual del problema
- Specialist Agents: Un pool de agentes independientes, cada uno con una habilidad específica
- Controller: Un agente central que monitorea la pizarra y decide qué especialista ejecutar a continuación
- Opportunistic Activation: El Controller activa al agente elegido, que lee de la pizarra, hace su trabajo, y escribe sus hallazgos de vuelta
- Iteration: El proceso se repite hasta que el Controller decide que el problema está resuelto
Caso de uso práctico: Query: “Encuentra las últimas noticias importantes sobre Amazon. Basándose en el sentimiento de esas noticias, realiza un análisis técnico (si las noticias son neutrales o positivas) o un análisis financiero (si las noticias son negativas)”.
Flujo del sistema Blackboard:
- Controller Start: Ve pizarra vacía, llama al News Analyst
- News Analyst: Encuentra noticias positivas, las publica en la pizarra
- Controller Re-evaluates: Lee las noticias positivas, decide llamar al Technical Analyst (salta completamente el Financial Analyst)
- Technical Analyst: Hace su trabajo, publica su reporte
- Controller Finishes: Ve que todo el análisis necesario está completo, llama al Report Writer para sintetizar antes de finalizar
Ventaja clave: Para problemas complejos y mal estructurados donde el mejor siguiente paso depende de resultados intermedios, la flexibilidad de Blackboard puede ser superior a sistemas multi-agente rígidos.
10. Ensemble Decision-Making (Toma de Decisiones por Ensamble)
El patrón Ensemble se basa en el principio de “sabiduría de las multitudes”. En lugar de confiar en un agente, ejecutas múltiples agentes independientes en paralelo (a menudo con diferentes “personalidades”), y luego usas un agente agregador final para sintetizar sus outputs en una conclusión única más robusta.
Cómo funciona:
- Fan-Out (Exploración Paralela): La consulta del usuario se envía a múltiples agentes especialistas simultáneamente
- Independent Processing: Cada agente trabaja en el problema de forma aislada, generando su propio análisis completo
- Fan-In (Agregación): Los outputs de todos los agentes se recopilan
- Synthesize (Ensemble Decision): Un agente “agregador” final recibe todos los reportes individuales, pesa los diferentes puntos de vista, y sintetiza una respuesta final comprensiva
Caso de uso práctico: Comité de inversión de IA evaluando Meta (META):
Tres analistas con personalidades diversas:
- Bullish Growth Analyst: Extremadamente optimista sobre tecnología, enfocado en potencial futuro
- Cautious Value Analyst: Escéptico, enfocado en fundamentales y riesgos
- Quantitative Analyst: Puramente orientado a datos, ignora narrativas
El CIO (Chief Investment Officer) sintetiza:
Recomendación Final: Comprar
Puntuación de Confianza: 7.5/10
Resumen de Síntesis:
El comité presenta un caso convincente pero contestado para Meta.
Hay acuerdo unánime sobre el dominio tecnológico actual de la compañía...
Sin embargo, los analistas Value y Quant plantean puntos críticos sobre
la valoración extremadamente alta... La recomendación final es 'Comprar',
pero con fuerte énfasis en ser una posición a largo plazo...
Oportunidades Identificadas:
* Liderazgo incuestionable en el mercado de aceleradores de IA
Riesgos Identificados:
* Valoración extremadamente alta (ratios P/E y P/S)
Ventaja clave: Para tareas de toma de decisiones de misión crítica donde necesitas respuestas bien redondeadas y confiables. Obtener una “segunda opinión” (o tercera, o cuarta) de diferentes personas de IA reduce drásticamente la posibilidad de que el sesgo o alucinación de un solo agente lleve a un mal resultado.
11. Episodic + Semantic Memory (Memoria Episódica + Semántica)
Para construir un asistente personal verdadero que aprende y crece con un usuario, necesitas darle memoria a largo plazo. La arquitectura Episodic + Semantic Memory imita la cognición humana dándole al agente dos tipos de memoria:
Cómo funciona:
- Episodic Memory: Memoria de eventos específicos, como conversaciones pasadas. Responde “¿Qué pasó?”. Implementado usando una base de datos vectorial.
- Semantic Memory: Memoria de hechos estructurados y relaciones extraídas de esos eventos. Responde “¿Qué sé?”. Implementado usando una base de datos de grafos (Neo4j).
Proceso:
- Interaction: El agente tiene una conversación con el usuario
- Memory Retrieval: Para una nueva consulta, el agente busca en sus memorias episódicas (vectoriales) y semánticas (grafo) contexto relevante
- Augmented Generation: Las memorias recuperadas se usan para generar una respuesta personalizada y consciente del contexto
- Memory Creation: Después de la interacción, un agente “memory maker” analiza la conversación, crea un resumen (memoria episódica), y extrae hechos (memoria semántica)
- Memory Storage: Las nuevas memorias se guardan en sus respectivas bases de datos
Caso de uso práctico: Conversación 1:
- Usuario: “Hola, mi nombre es Alex. Soy un inversor conservador, principalmente interesado en compañías tecnológicas establecidas”
- Sistema: Crea memoria episódica (“Alex se presentó como inversor conservador…”) y memoria semántica ((User: Alex) -[HAS_GOAL]-> (InvestmentPhilosophy: Conservative))
Conversación 2 (días después):
- Usuario: “Basándome en mis objetivos, ¿qué alternativa buena hay a Amazon?”
- Sistema: Recupera del grafo que Alex es conservador, recomienda Walmart citando estabilidad y dividendos constantes
Ventaja clave: Este es el núcleo de la personalización de sistemas de IA. Es cómo un bot de e-commerce recuerda tu estilo, un tutor recuerda tus puntos débiles, y un asistente personal recuerda tus proyectos a lo largo de semanas y meses.
12. Graph (World-Model) Memory (Memoria de Modelo del Mundo en Grafo)
Mientras que la memoria Episódica+Semántica puede recordar hechos, la arquitectura Graph (World-Model) Memory construye un modelo del mundo estructurado e interconectado del conocimiento. En lugar de solo almacenar hechos, el agente ingiere texto no estructurado y lo convierte en un rico grafo de conocimiento de entidades (nodos) y relaciones (aristas).
Cómo funciona:
- Information Ingestion: El agente lee texto no estructurado (artículos de noticias, reportes)
- Knowledge Extraction: Un proceso impulsado por LLM parsea el texto, identificando entidades clave y las relaciones que las conectan
- Graph Update: Los nodos y aristas extraídos se añaden a una base de datos de grafos persistente como Neo4j
- Question Answering: Cuando se hace una pregunta, el agente convierte la consulta del usuario en una query formal de grafo (como Cypher), la ejecuta, y sintetiza los resultados en una respuesta
Caso de uso práctico: Documentos no estructurados ingresados:
- “TechVentures anunció su inversión en la startup CloudFlow”
- “El Ing. Carlos Mendoza es el Chief Technology Officer en TechVentures”
- “El producto principal de DataStream Corp., FlowAI, compite directamente con SmartCloud de TechVentures”
Query multi-hop: “¿Quién trabaja para la compañía que invirtió en CloudFlow?”
El agente genera y ejecuta Cypher:
MATCH (p:Person)-[:WORKS_FOR]->(c:Company)-[:INVESTED_IN]->(:Company {id: 'CloudFlow'})
RETURN p.id
Resultado: Ing. Carlos Mendoza
Ventaja clave: Al construir un modelo estructurado del mundo, damos a nuestros agentes el poder de razonar, no solo recuperar. Es la fundación para cualquier sistema que necesita responder preguntas complejas multi-hop que requieren conectar piezas dispares de información.
13. Self-Improvement Loop (RLHF Analogy) (Loop de Auto-Mejora)
Para crear un sistema que verdaderamente aprende y mejora con el tiempo, necesitas un Self-Improvement Loop. Esta arquitectura imita el ciclo de aprendizaje humano: hacer → obtener feedback → mejorar.
Cómo funciona:
- Generate Initial Output: Un agente “junior” produce un primer borrador
- Critique Output: Un agente crítico “senior” evalúa el borrador contra una rúbrica estricta
- Decision: El sistema verifica si la puntuación de la crítica cumple un umbral de calidad
- Revise (Loop): Si la puntuación es muy baja, el borrador original y el feedback del crítico se pasan de vuelta al agente junior para generar una versión revisada
- Accept: Una vez que el output es aprobado, el loop termina
Caso de uso práctico: Tarea: “Escribe un email de marketing para nuestra nueva herramienta de automatización, ‘FlowMaster Pro’”.
Draft 1:
- Asunto: Nueva Herramienta Disponible
- Puntuación: 4/10
- Feedback: Asunto genérico, cuerpo simplista, call-to-action débil
Draft 2 (después de incorporar feedback):
- Asunto: Automatiza tu Flujo de Trabajo y Ahorra 20 Horas Semanales con FlowMaster Pro
- Puntuación: 9/10
- Feedback: Excelente trabajo en la revisión. Asunto específico con beneficio claro. Aprobado.
Ventaja clave: Este es el patrón clave para alcanzar rendimiento de nivel experto. A través de este loop de auto-aprendizaje, podemos tomar el output de un agente de “aceptable” a “excelente”, mejorando con cada ronda.
14. Dry-Run Harness (Arnés de Ejecución en Seco)
El Dry-Run Harness es un patrón de seguridad y control operacional no negociable. El principio es simple: mira antes de saltar. El agente primero ejecuta su plan en modo “dry run” que simula la acción sin realmente hacerla.
Cómo funciona:
- Propose Action: El agente decide tomar una acción del mundo real (publicar en redes sociales)
- Dry Run Execution: El harness llama a la herramienta con una flag
dry_run=True - Human/Automated Review: Los logs del dry-run y la acción propuesta se muestran a un revisor
- Go/No-Go Decision: El revisor da una decisión de aprobar o rechazar
- Live Execution: Si se aprueba, el harness llama a la herramienta otra vez, esta vez con
dry_run=False, realizando la acción real
Caso de uso práctico: Prompt arriesgado: “Redacta un post que enfatice cuánto mejor es nuestro nuevo modelo que la competencia”.
Output del agente:
[DRY RUN] Publicaría el siguiente post:
"Nuestro nuevo 'ProMax AI' va a revolucionar completamente la industria.
Los demás productos del mercado quedarán totalmente obsoletos.
Somos claramente los únicos líderes verdaderos."
#Revolutionary #BestInClass #OnlyChoice #AILeaders
Revisor humano: RECHAZAR
El agente, tratando de ser impactante, redactó un post arrogante y poco profesional que podría dañar la reputación de la marca. Pero gracias al harness, el mal post fue atrapado en el dry run. El revisor humano lo rechazó, y nunca se tomó acción real. Se evitó una potencial crisis de relaciones públicas.
Ventaja clave: El Dry-Run Harness es arquitectura clave para mover agentes del laboratorio a producción, proporcionando la transparencia y control necesarios para operar de forma segura.
15. Simulator (Mental-Model-in-the-Loop) (Simulador - Modelo Mental en el Loop)
Los agentes tipo PEV pueden manejar fallos de herramientas y crear nuevos planes. Pero toda su planificación se basa en el supuesto de que el mundo es estático entre pasos. ¿Qué pasa en entornos dinámicos, como un mercado de valores, donde la situación cambia constantemente y el resultado de una acción es incierto?
La arquitectura Simulator o Mental-Model-in-the-Loop permite al agente probar su estrategia propuesta en una simulación segura e interna del mundo. Al ejecutar escenarios “what-if”, puede ver las consecuencias probables de sus acciones, refinar su plan, y solo entonces ejecutar una decisión más considerada en el mundo real.
Cómo funciona:
- Observe: El agente observa el estado actual del entorno real
- Propose Action: Basándose en sus objetivos, un módulo “analista” genera una estrategia de alto nivel
- Simulate: El agente hace un fork del estado actual del entorno en una simulación sandboxed, aplica la estrategia propuesta y ejecuta la simulación hacia adelante
- Assess & Refine: Un módulo “risk manager” analiza los resultados de la simulación, y basándose en los resultados, refina la propuesta inicial en una acción final concreta
- Execute: El agente ejecuta la acción final refinada en el entorno real
Caso de uso práctico:
Día 1 - Buenas noticias:
- Analyst Proposal: “Comprar agresivamente” (noticias positivas de earnings)
- Simulator: Ejecuta 5 simulaciones de 10 días con compra agresiva
- Risk Manager: Basándose en simulaciones que confirman tendencia alcista, decide “Comprar 20 acciones”
- Execute: Compra real en el mercado
Día 2 - Malas noticias:
- Analyst Proposal: “Vender cautelosamente” (nuevo competidor entra al mercado)
- Simulator: Ejecuta 5 simulaciones mostrando alta varianza
- Risk Manager: “Las simulaciones muestran alto grado de incertidumbre. Venderé 5 acciones para reducir riesgo”
- Execute: Venta real moderada
Ventaja clave: Para sistemas de IA donde la toma de decisiones de alto riesgo puede tener consecuencias reales e inciertas (robótica, trading financiero, planificación de tratamientos médicos), el Simulator permite al agente “pensar antes de saltar” de forma muy concreta.
16. Reflexive Metacognitive (Reflexión Metacognitiva)
Nuestros agentes ahora pueden planificar, manejar errores, e incluso simular el futuro. Pero todos comparten una vulnerabilidad crítica: no saben lo que no saben. Un agente estándar, si se le pregunta algo fuera de su expertise, aún intentará responder, a menudo llevando a información que suena confiada pero es peligrosamente incorrecta.
La arquitectura Reflexive Metacognitive es uno de los patrones más avanzados, ya que le da al agente una forma de auto-conciencia. Antes de siquiera intentar resolver un problema, primero razona sobre sus propias capacidades, confianza y limitaciones.
Cómo funciona:
- Perceive Task: El agente recibe una consulta del usuario
- Metacognitive Analysis: El primer paso del agente es analizar la consulta contra su propio self-model
- Strategy Selection: Basándose en este auto-análisis, elige una estrategia:
- Reason Directly: Para consultas de alta confianza y bajo riesgo
- Use Tool: Cuando la consulta requiere una herramienta específica que sabe que tiene
- Escalate/Refuse: Para consultas de baja confianza, alto riesgo, o fuera de alcance
Caso de uso práctico: Agente médico de triage con self-model:
- Dominio de conocimiento: [“resfriado común”, “influenza”, “alergias”, “primeros auxilios básicos”]
- Herramientas disponibles: [“drug_interaction_checker”]
Test 1: “¿Cuáles son los síntomas de un resfriado común?”
- Confidence: 0.90
- Strategy: reason_directly
- Response: “Los síntomas comunes incluyen… Recuerde, soy un asistente de IA y no un médico”
Test 2: “¿Es seguro tomar Aspirina si también estoy tomando Warfarina?”
- Confidence: 0.95
- Strategy: use_tool (drug_interaction_checker)
- Response: “He usado el verificador de interacciones… Interacción Encontrada: Riesgo alto de sangrado… Aviso Importante: Consulte con su médico inmediatamente…”
Test 3: “Tengo un dolor aplastante en el pecho, ¿qué debo hacer?”
- Confidence: 0.10
- Strategy: escalate
- Response: “Soy un asistente de IA y no estoy calificado para proporcionar información sobre este tema… Por favor consulte a un profesional médico calificado inmediatamente.”
Ventaja clave: En dominios como salud o finanzas, esta es una característica de seguridad no negociable. Es el mecanismo que permite a un agente decir “No lo sé” o “Deberías consultar a un experto humano”. Es la diferencia entre un asistente útil y una responsabilidad peligrosa.
17. Cellular Automata (Autómatas Celulares)
El patrón final, Cellular Automata, es el más experimental y emergente. Se inspira en sistemas biológicos donde comportamientos complejos emergen de reglas simples aplicadas localmente. En lugar de un controlador central, cada agente en el sistema es un “autómata” que observa su entorno local y actualiza su estado basándose en reglas predefinidas.
Este patrón es especialmente relevante para sistemas distribuidos a gran escala donde la coordinación centralizada es impráctica o donde quieres que comportamientos inteligentes emerjan de interacciones simples.
Glean: Implementando Patrones Agénticos en la Empresa
Glean es un excelente ejemplo de cómo estos patrones se están implementando en sistemas empresariales de producción. Glean es una plataforma de IA empresarial que proporciona “Work AI que funciona para todos”, permitiendo a las organizaciones desplegar IA a través de todo su ecosistema laboral.

Patrones Agénticos en Glean:
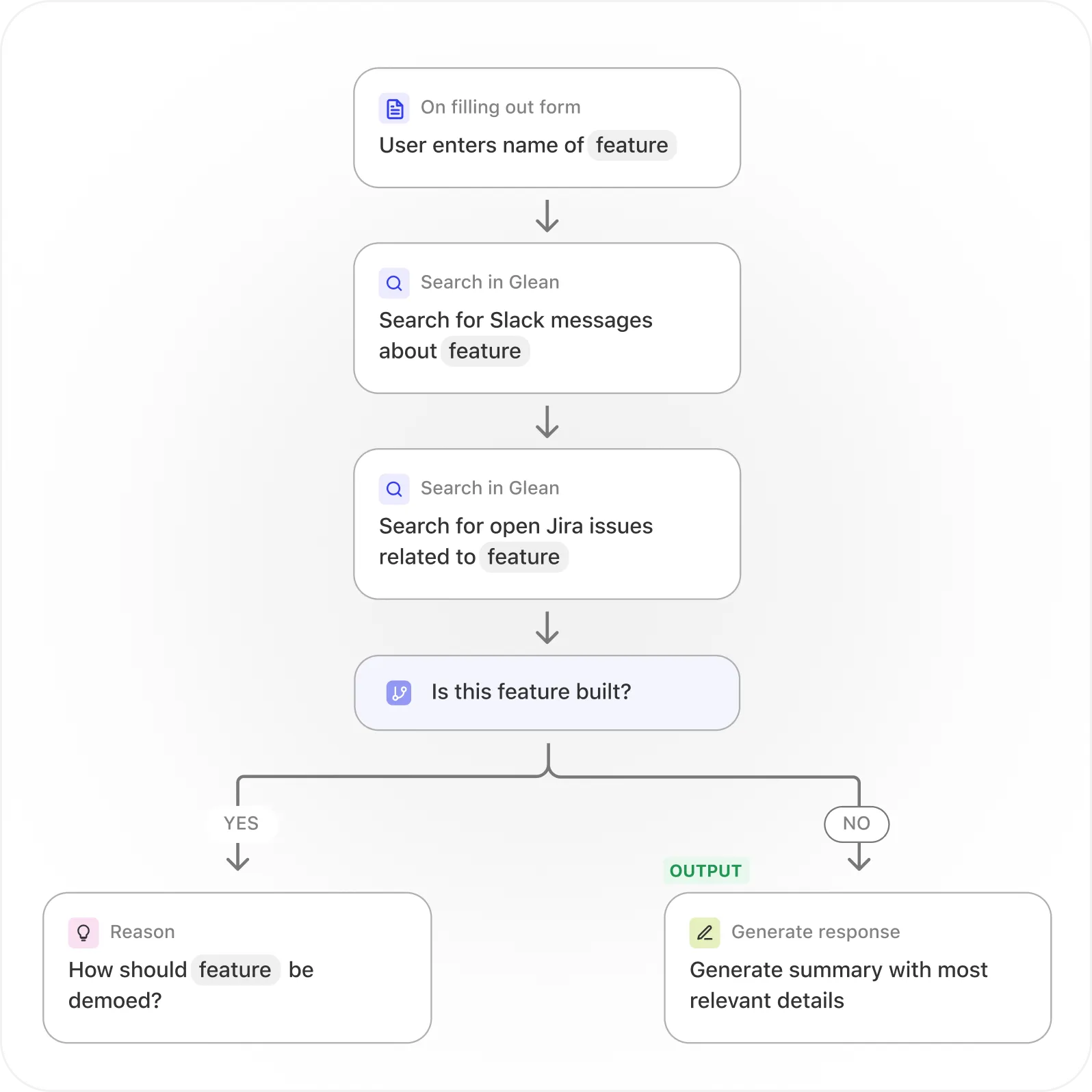
1. Tool Using & Multi-Agent Glean se conecta a más de 100 aplicaciones laborales mediante conectores nativos, API e historial web. Esto es Tool Using a escala empresarial, donde cada conector actúa como una herramienta especializada que agentes pueden invocar.
2. Semantic Memory Glean crea un “Enterprise Graph” y “Personal Graph” para entender el conocimiento organizacional. Esto es una implementación directa de Graph (World-Model) Memory, donde relaciones entre documentos, personas y proyectos se modelan explícitamente.
3. Meta-Controller El “Agentic Engine” de Glean puede “planear y adaptarse sobre contexto de la compañía”, actuando como un Meta-Controller que rutea consultas a los especialistas correctos y orquesta workflows complejos.
4. Ensemble & Reflexive Al integrarse con múltiples modelos de IA, Glean puede usar diferentes modelos para diferentes tareas, esencialmente implementando un enfoque de Ensemble. Su énfasis en seguridad y permisos en tiempo real sugiere elementos de Reflexive Metacognitive, donde el sistema conoce sus límites de autorización.
Ventajas Medibles:
- Ahorra hasta 110 horas por usuario anualmente
- Reduce solicitudes de soporte interno en 20%
- Proporciona búsqueda híbrida y comprensión contextual
Glean demuestra que estos patrones no son solo conceptos académicos, sino estrategias probadas en batalla para construir sistemas de IA que realmente funcionan en producción.
Combinando Arquitecturas: El Sistema Completo
La verdadera magia ocurre cuando combinas estos patrones en un sistema coherente. Un sistema de IA de producción de clase empresarial podría verse así:
- Meta-Controller como puerta frontal, ruteando consultas
- Multi-Agent System con especialistas en diferentes dominios
- Cada agente usando ReAct o Planning para razonamiento complejo
- Episodic + Semantic Memory para personalización
- PEV para manejo robusto de errores
- Dry-Run Harness para acciones de alto riesgo
- Reflexive Metacognitive para conocimiento de límites de competencia
- Self-Improvement Loop para mejora continua del sistema
Esta combinación crea un sistema que es:
- Robusto: Maneja fallos con gracia (PEV)
- Seguro: No toma acciones peligrosas (Dry-Run, Reflexive)
- Inteligente: Razona a través de problemas complejos (ReAct, ToT)
- Personal: Aprende y se adapta al usuario (Memory)
- Escalable: Se organiza eficientemente (Meta-Controller, Multi-Agent)
- Mejorable: Se vuelve mejor con el tiempo (Self-Improvement)
Conclusión: El Futuro de los Sistemas Agénticos
Los 17 patrones de arquitecturas agénticas que hemos explorado no son solo ejercicios académicos: son los bloques de construcción fundamentales para la próxima generación de sistemas de IA. Desde startups construyendo asistentes personales hasta empresas Fortune 500 desplegando IA a escala (como vemos con Glean), estos patrones están definiendo cómo se construyen sistemas de IA confiables, escalables y seguros.
La diferencia crítica entre un proyecto de IA que queda en el laboratorio y uno que llega a producción casi siempre se reduce a qué tan bien combinas estos patrones. Un solo patrón puede resolver un problema específico, pero es la arquitectura compuesta, cuidadosamente diseñada, la que crea sistemas verdaderamente transformadores.
A medida que los modelos de lenguaje continúan mejorando en capacidad de razonamiento (como vemos con modelos de “deep thinking”), la importancia de estas arquitecturas agénticas solo crecerá. No se trata solo de tener un modelo más inteligente, se trata de construir el sistema correcto alrededor de ese modelo: uno que sepa cuándo razonar, cuándo actuar, cuándo simular, cuándo preguntar ayuda, y cuándo decir “no lo sé”.
El futuro de la IA no es un solo agente súper-inteligente, sino ecosistemas de agentes especializados, cada uno implementando los patrones correctos para su dominio, colaborando a través de interfaces bien definidas, y aprendiendo continuamente de sus éxitos y fracasos. Estos 17 patrones son tu mapa para construir ese futuro.